如果你用一张GTX1080TI跑Imagenet,一个epoch需要8小时,我相信你肯定会发疯的——没错,一开始的我就是这样。都说了人生苦短,我用Python,诸位炼丹师怎么能把时间浪费在漫长的炼丹过程中呢?经过漫长的摸索和尝试,我成功地将Imagenet的训练过程加快了两倍(同等硬件条件下)。 DALI (大力)出奇迹😂。
症状
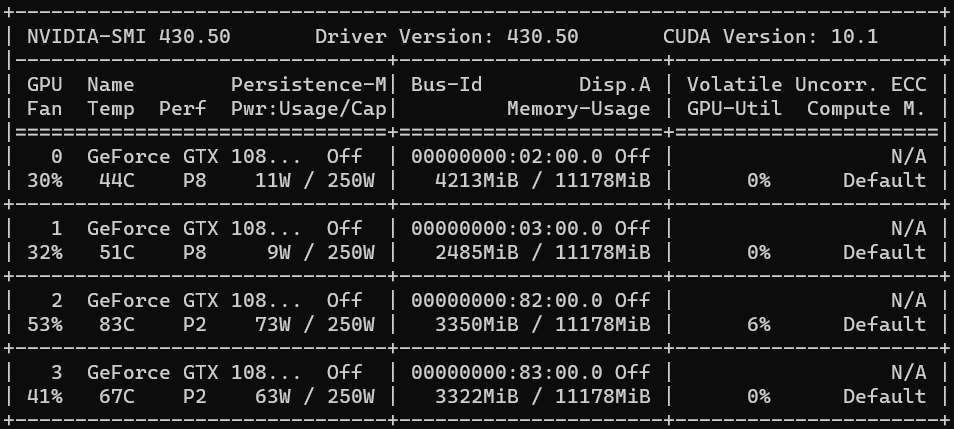
- 训练跑起来了,显存占用也很正常。
- GPU利用率低,常常是0%,很偶然飙到比较高然后又会降回来。
- 训练很慢,感觉快要忍不下去了,严重怀疑是不是根本没动过……
- 即使是四卡一个epoch也要跑3小时,怀疑人生。
一些应该有用的技巧
model.cuda()
这……恐怕GPU要在一旁偷笑。记得要开启GPU加速,不然CPU跑的累死累活都没用。
torch.backends.cudnn.benchmark = True
如果你的计算图(模型)不会改变,那么加上这行命令会快些,反之则会慢些。
trainloader = torch.utils.data.DataLoader(
..., num_workers=8, pin_memory=True)在定义DataLoader的时候使用合适的num_workers并设置pin_memory=True。num_workers可以指定加载数据用的并行数,一般设置为GPU数量的两倍或者四倍即可,亲测太高的num_workers也没用,一大堆线程都是休眠状态。pin_memory=True可以开启显存预分配,应该是可以加快初次加载的速度。
for batch_idx, (data, target) in enumerate(trainloader):
data, target = data.cuda(non_blocking=True), target.cuda(non_blocking=True)
data, target = Variable(data), Variable(target)
......设置non_blocking=True可以防止多GPU同时读取内存导致堵塞。据说Variable是有用的,我也不知道有没有用,还是加上吧。
os.environ["CUDA_VISIBLE_DEVICES"] = "0,1,2,3"
model = XXX
model.cuda()
model = nn.DataParallel(model)这个就不用我多说了,多卡用起来!
此外,把数据集直接存在内存里也可以极大地加速数据的读取。
网上看到有建议用torch.nn.parallel.DistributedDataParallel的,这个我实际用下来没感觉有明显的不同,配置起来也会繁琐一点,这里我就不提了。
什么?你试完了以上操作都没感觉有所加快(除了多卡,多卡的加速还是很明显的)?不急,我也是这样的,下面就给大家介绍一种很少被提到的,但却是立竿见影的方法。
DALI (大力)出奇迹
英伟达数据加载库 DALI 是一个便捷式开源库,用于图像或视频的解码及增强,从而加速深度学习应用。通过并行训练和预处理过程,减少了延迟及训练时间,并为当下流行的深度学习框架中的内置数据加载器及数据迭代器提供了一个嵌入式替代器,便于集成或重定向至不同框架。
DALI的下载地址:https://github.com/NVIDIA/DALI/releases
也可以通过pip安装(DALI v0.24.0):
# For CUDA 10
pip install --extra-index-url https://developer.download.nvidia.com/compute/redist/ nvidia-dali-cuda100==0.24.0
# For CUDA 11
pip install --extra-index-url https://developer.download.nvidia.com/compute/redist/ nvidia-dali-cuda110==0.24.0直接使用会比较麻烦,要自己重定义很多东西,我直接拿了别人做好的pipeline来用,地址:https://github.com/tanglang96/DataLoaders_DALI
使用方法很简单,以cifar10数据集为例,Imagenet类似:
from base import DALIDataloader
from cifar10 import HybridTrainPipe_CIFAR
pip_train = HybridTrainPipe_CIFAR(batch_size=TRAIN_BS,
num_threads=NUM_WORKERS,
device_id=0,
data_dir=IMG_DIR,
crop=CROP_SIZE,
world_size=1,
local_rank=0,
cutout=0)
train_loader = DALIDataloader(pipeline=pip_train,
size=CIFAR_IMAGES_NUM_TRAIN,
batch_size=TRAIN_BS,
onehot_label=True)
for i, data in enumerate(train_loader): # Using it just like PyTorch dataloader
images = data[0].cuda(non_blocking=True)
labels = data[1].cuda(non_blocking=True)
总的来说就是像往常一样用就好了,只需要在数据集加载部分做文章。
加速的效果是如何的呢?
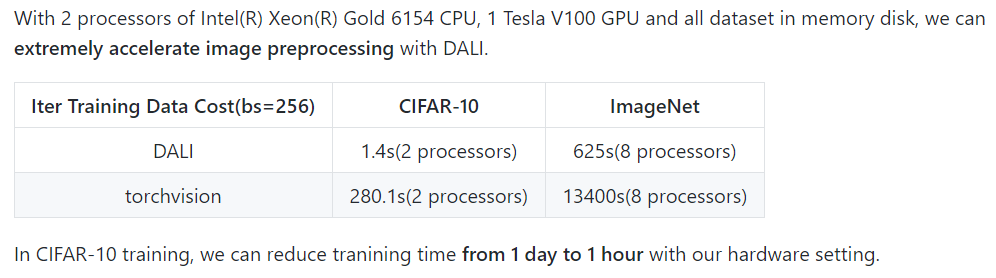
原来4小时,现在10分钟,啊?!真的吗?
亲测小鱼的四卡GTX1080TI,数据集是存在机械硬盘中的。训练一个epoch,原来需要3小时,现在只需要1小时多一点。GPU利用率也起来了,大部分时间都是高负荷地跑。嗯,看来是真的有效!
不过,小鱼在训练的过程中发现训练的速度会慢慢变慢,一开始的20%是飞快的,后面就慢下来了。原因未知。知道的朋友在下面留言下呗。